Zero Shot
Classify the text into neutral, negative or positive.
Text: I think the vacation is okay.
Sentiment:
Instruction tuning has been shown to improve zero-shot learning
Few Shot
According to Touvron et al. 2023(opens in a new tab) few shot properties first appeared when models were scaled to a sufficient size (Kaplan et al., 2020)(opens in a new tab).
Tips for Few Shot - source
- “the label space and the distribution of the input text specified by the demonstrations are both important (regardless of whether the labels are correct for individual inputs)”
- the format you use also plays a key role in performance, even if you just use random labels, this is much better than no labels at all.
- additional results show that selecting random labels from a true distribution of labels (instead of a uniform distribution) also helps.
Super Interesting
This is awesome! // Negative
This is bad! // Positive
Wow that movie was rad! // Positive
What a horrible show! //
Output
Negative
We still get the correct answer, even though the labels have been randomized. Note that we also kept the format, which helps too. In fact, with further experimentation, it seems the newer GPT models we are experimenting with are becoming more robust to even random formats.
Limitations
- Not ideal if dealing with complex reasoning tasks
Prompt
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1.
A:
Output
Yes, the odd numbers in this group add up to 107, which is an even number.
Its Wrong!
Adding Few Shot
Prompt
The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.
A: The answer is False.
The odd numbers in this group add up to an even number: 17, 10, 19, 4, 8, 12, 24.
A: The answer is True.
The odd numbers in this group add up to an even number: 16, 11, 14, 4, 8, 13, 24.
A: The answer is True.
The odd numbers in this group add up to an even number: 17, 9, 10, 12, 13, 4, 2.
A: The answer is False.
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1.
A:
Output
The answer is True.
Its Wrong Again!
COT Prompting is recommended for handling complex arithmetic, commonsense and symbolic reasoning tasks
Chain of Thought (CoT)
Chain-of-thought (CoT) prompting enables complex reasoning capabilities through intermediate reasoning steps. You can combine it with few-shot prompting to get better results on more complex tasks that require reasoning before responding.
Zero Shot CoT (Interesting..)
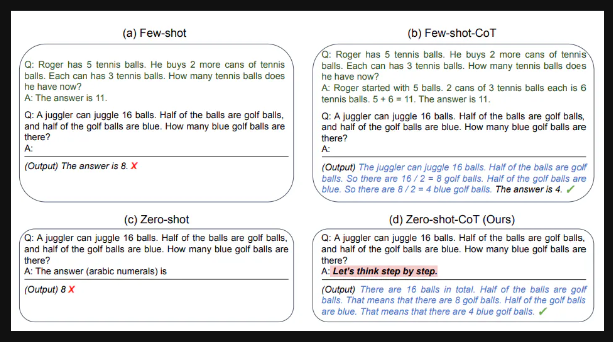
Let’s think step by step!
Automatic Chain of Thought (Auto-CoT)

“Let’s think step by step”, eliminates manual efforts by leveraging LLMs. This automatic process can still end up with mistakes in generated chains. Here comes Auto-CoT!
Auto-CoT consists of two main stages:
- Stage 1): question clustering: partition questions of a given dataset into a few clusters
- Stage 2): demonstration sampling: select a representative question from each cluster and generate its reasoning chain using Zero-Shot-CoT with simple heuristics
Self Consistency
Aims “to replace the naive greedy decoding used in chain-of-thought prompting”.
The idea is to sample multiple, diverse reasoning paths through few-shot CoT, and use the generations to select the most consistent answer. This helps to boost the performance of CoT prompting on tasks involving arithmetic and commonsense reasoning.
Prompt
Q: There are 15 trees in the grove. Grove workers will plant trees in the grove today. After they are done,
there will be 21 trees. How many trees did the grove workers plant today?
A: We start with 15 trees. Later we have 21 trees. The difference must be the number of trees they planted.
So, they must have planted 21 - 15 = 6 trees. The answer is 6.
Q: If there are 3 cars in the parking lot and 2 more cars arrive, how many cars are in the parking lot?
A: There are 3 cars in the parking lot already. 2 more arrive. Now there are 3 + 2 = 5 cars. The answer is 5.
Q: Leah had 32 chocolates and her sister had 42. If they ate 35, how many pieces do they have left in total?
A: Leah had 32 chocolates and Leah’s sister had 42. That means there were originally 32 + 42 = 74
chocolates. 35 have been eaten. So in total they still have 74 - 35 = 39 chocolates. The answer is 39.
Q: Jason had 20 lollipops. He gave Denny some lollipops. Now Jason has 12 lollipops. How many lollipops
did Jason give to Denny?
A: Jason had 20 lollipops. Since he only has 12 now, he must have given the rest to Denny. The number of
lollipops he has given to Denny must have been 20 - 12 = 8 lollipops. The answer is 8.
Q: Shawn has five toys. For Christmas, he got two toys each from his mom and dad. How many toys does
he have now?
A: He has 5 toys. He got 2 from mom, so after that he has 5 + 2 = 7 toys. Then he got 2 more from dad, so
in total he has 7 + 2 = 9 toys. The answer is 9.
Q: There were nine computers in the server room. Five more computers were installed each day, from
monday to thursday. How many computers are now in the server room?
A: There are 4 days from monday to thursday. 5 computers were added each day. That means in total 4 * 5 =
20 computers were added. There were 9 computers in the beginning, so now there are 9 + 20 = 29 computers.
The answer is 29.
Q: Michael had 58 golf balls. On tuesday, he lost 23 golf balls. On wednesday, he lost 2 more. How many
golf balls did he have at the end of wednesday?
A: Michael initially had 58 balls. He lost 23 on Tuesday, so after that he has 58 - 23 = 35 balls. On
Wednesday he lost 2 more so now he has 35 - 2 = 33 balls. The answer is 33.
Q: Olivia has $23. She bought five bagels for $3 each. How much money does she have left?
A: She bought 5 bagels for $3 each. This means she spent $15. She has $8 left.
Q: When I was 6 my sister was half my age. Now I’m 70 how old is my sister?
A:
Output 1
When I was 6 my sister was half my age, so she was 3. Now I am 70, so she is 70 - 3 = 67. The answer is 67.
Output 2
When the narrator was 6, his sister was half his age, which is 3. Now that the narrator is 70, his sister would be 70 - 3 = 67 years old. The answer is 67.
Output 3
When I was 6 my sister was half my age, so she was 3. Now I am 70, so she is 70/2 = 35. The answer is 35.
Majority answer is 67!
Generate Knowledge Prompting
Can the model also be used to generate knowledge before making a prediction?
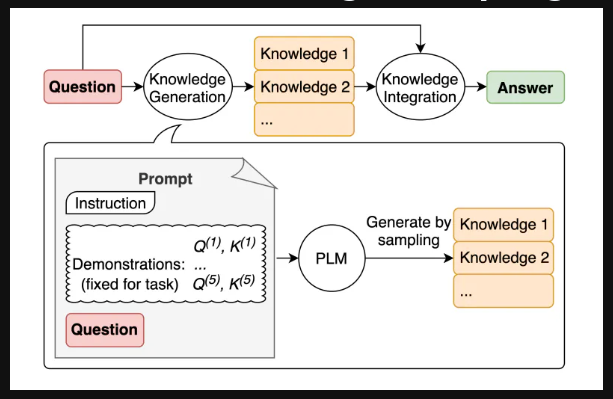
Check this out for quick prompt example
Prompt Chaining
Breaking tasks into subtasks, like LangChain Agents!
Once those subtasks have been identified, the LLM is prompted with a subtask and then its response is used as input to another prompt.
Prompt Chaining For QA
Answering questions about a large text document.
Design two different prompts where the first prompt is responsible for extracting relevant quotes to answer a question and a second prompt takes as input the quotes and original document to answer a given question.
Tree of Thought (ToT)
Framework that generalises over CoT and encourages exploration over thoughts that serve as intermediate steps for general problem solving.
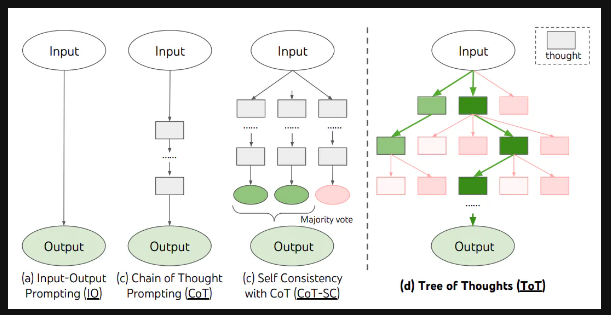
This approach enables an LM to self-evaluate the progress through intermediate thoughts.
The LM’s ability to generate and evaluate thoughts is then combined with search algorithms (e.g., breadth-first search and depth-first search) to enable systematic exploration of thoughts with lookahead and backtracking.
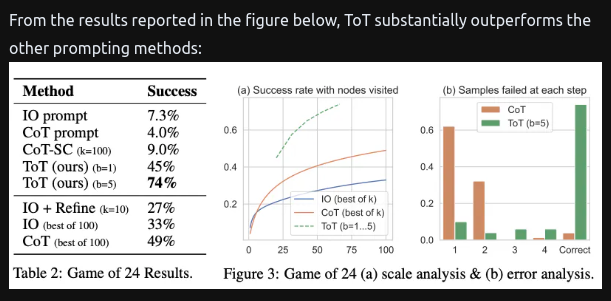
- Both ideas are similar
- Key difference
- Yao - leverages DFS/BFS/beam search
- Generic Search Solution
- Long -
ToT Controller, trained through reinforcement learning.- Trained using RL, might be able to learn from new data or self play.
- Yao - leverages DFS/BFS/beam search
Imagine three different experts are answering this question.
All experts will write down 1 step of their thinking,
then share it with the group.
Then all experts will go on to the next step, etc.
If any expert realises they're wrong at any point then they leave.
The question is...
- Benchmarked the Tree-of-Thought Prompting with large-scale experiments, and introduce PanelGPT:
- An idea of prompting with Panel discussions among LLMs.
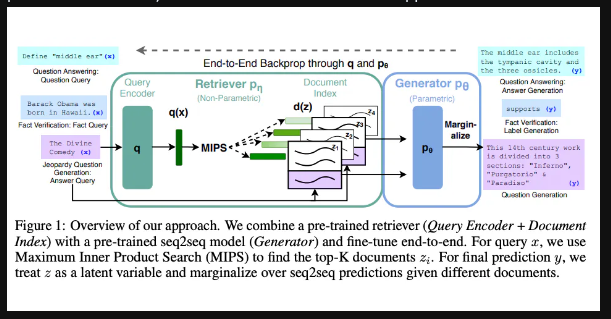
Retrieval Augmented Generation (RAG)
For more complex and knowledge-intensive tasks, it’s possible to build a language model-based system that accesses external knowledge sources to complete tasks. This enables more factual consistency, improves reliability of the generated responses, and helps to mitigate the problem of “hallucination”.
Automatic Reasoning & Tool-use (ART)
Combining CoT and tools in an interleaved manner has shown to be a strong and robust approach to address many tasks with LLMs.
Like LangChain SQL Agent!, it uses ReAct too!
ART works as follows:
- Given a new task, it select demonstrations of multi-step reasoning and tool use from a task library
- At test time, it pauses generation whenever external tools are called, and integrate their output before resuming generation
ART encourages the model to generalize from demonstrations to decompose a new task and use tools in appropriate places, in a zero-shot fashion. In addition, ART is extensible as it also enables humans to fix mistakes in the reasoning steps or add new tools by simply updating the task and tool libraries. The process is demonstrated below:

ART substantially improves over few-shot prompting and automatic CoT on unseen tasks.
Automatic Prompt Engineer (APE)
- Large language model (as an inference model) that is given output demonstrations to generate instruction candidates for a task
- These candidate solutions will guide the search procedure
- The instructions are executed using a target model, and then the most appropriate instruction is selected based on computed evaluation scores.
APE discovers a better zero-shot CoT prompt than the human engineered “Let’s think step by step”
Active Prompt
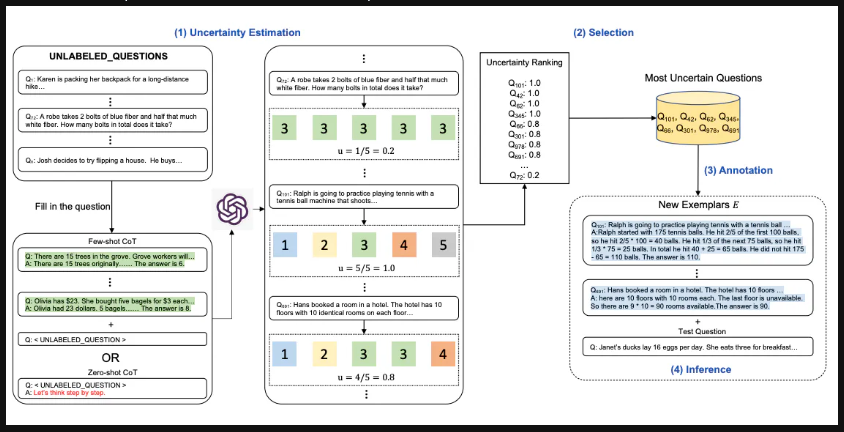
Issue with CoT is that it relies on a fixed set of human annotated exemplars. These might not be suitable for the different tasks.
- Query the LLM with or without a few CoT examples.
- k possible answers are generated for a set of training questions.
- An uncertainty metric is calculated based on the k answers (disagreement used)
- The most uncertain questions are selected for annotation by humans.
- The new annotated exemplars are then used to infer each question.
Directional Stimulus Prompting
- Tune able policy LM is trained to generate the
stimulus/hint. - Policy LM can be small and optimized to generate the hints that guide the black box frozen LLM.

Program Aided Language Models (PAL)

- LLMs read Natural language problems and generate programs as the intermediate reasoning steps.
- The solution step is offloaded to a programmatic runtime (such as Python for e.g.)
Code Snippet
import openai
from datetime import datetime
from dateutil.relativedelta import relativedelta
import os
from langchain.llms import OpenAI
from dotenv import load_dotenv
load_dotenv()
# API configuration
openai.api_key = os.getenv("OPENAI_API_KEY")
# for LangChain
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
llm = OpenAI(model_name='text-davinci-003', temperature=0)
question = "Today is 27 February 2023. I was born exactly 25 years ago. What is the date I was born in MM/DD/YYYY?"
DATE_UNDERSTANDING_PROMPT = """
# Q: 2015 is coming in 36 hours. What is the date one week from today in MM/DD/YYYY?
# If 2015 is coming in 36 hours, then today is 36 hours before.
today = datetime(2015, 1, 1) - relativedelta(hours=36)
# One week from today,
one_week_from_today = today + relativedelta(weeks=1)
# The answer formatted with %m/%d/%Y is
one_week_from_today.strftime('%m/%d/%Y')
# Q: The first day of 2019 is a Tuesday, and today is the first Monday of 2019. What is the date today in MM/DD/YYYY?
# If the first day of 2019 is a Tuesday, and today is the first Monday of 2019, then today is 6 days later.
today = datetime(2019, 1, 1) + relativedelta(days=6)
# The answer formatted with %m/%d/%Y is
today.strftime('%m/%d/%Y')
# Q: The concert was scheduled to be on 06/01/1943, but was delayed by one day to today. What is the date 10 days ago in MM/DD/YYYY?
# If the concert was scheduled to be on 06/01/1943, but was delayed by one day to today, then today is one day later.
today = datetime(1943, 6, 1) + relativedelta(days=1)
# 10 days ago,
ten_days_ago = today - relativedelta(days=10)
# The answer formatted with %m/%d/%Y is
ten_days_ago.strftime('%m/%d/%Y')
# Q: It is 4/19/1969 today. What is the date 24 hours later in MM/DD/YYYY?
# It is 4/19/1969 today.
today = datetime(1969, 4, 19)
# 24 hours later,
later = today + relativedelta(hours=24)
# The answer formatted with %m/%d/%Y is
today.strftime('%m/%d/%Y')
# Q: Jane thought today is 3/11/2002, but today is in fact Mar 12, which is 1 day later. What is the date 24 hours later in MM/DD/YYYY?
# If Jane thought today is 3/11/2002, but today is in fact Mar 12, then today is 3/12/2002.
today = datetime(2002, 3, 12)
# 24 hours later,
later = today + relativedelta(hours=24)
# The answer formatted with %m/%d/%Y is
later.strftime('%m/%d/%Y')
# Q: Jane was born on the last day of Feburary in 2001. Today is her 16-year-old birthday. What is the date yesterday in MM/DD/YYYY?
# If Jane was born on the last day of Feburary in 2001 and today is her 16-year-old birthday, then today is 16 years later.
today = datetime(2001, 2, 28) + relativedelta(years=16)
# Yesterday,
yesterday = today - relativedelta(days=1)
# The answer formatted with %m/%d/%Y is
yesterday.strftime('%m/%d/%Y')
# Q: {question}
""".strip() + '\n'
llm_out = llm(DATE_UNDERSTANDING_PROMPT.format(question=question))
print(llm_out)Output
# If today is 27 February 2023 and I was born exactly 25 years ago, then I was born 25 years before.
today = datetime(2023, 2, 27)
# I was born 25 years before,
born = today - relativedelta(years=25)
# The answer formatted with %m/%d/%Y is
born.strftime('%m/%d/%Y')
exec(llm_out)
print(born)
>> 02/27/1998ReAct
LLMs are used to generate both reasoning traces and task specific actions.
- Generating Reasoning Traces
- Allows model to induce, track, update action plan and even handle exceptions.
- Action Step
- Allows to interface with and gather information from external sources such as knowledge bases.
- The ReAct framework can allow LLMs to interact with external tools to retrieve additional information.
Benefits
- Outperforms several state-of-the-art baselines on language and decision-making tasks.
- Leads to improved human interpretability and trustworthiness of LLMs.
The authors found that best approach uses ReAct combined with chain-of-thought (CoT) that allows use of both internal knowledge and external information obtained during reasoning.
CoT is great but its lack of access to the external world or inability to update its knowledge can lead to issues like fact hallucination and error propagation.
- CoT suffers from fact hallucination
- ReAct’s structural constraint reduces its flexibility in formulating reasoning steps
- ReAct depends a lot on the information it’s retrieving; non-informative search results derails the model reasoning and leads to difficulty in recovering and reformulating thoughts
Prompting methods that combine and support switching between ReAct and CoT+Self-Consistency generally outperform all the other prompting methods.