This is not a details review of the paper, its more like notes: For detailed info checkout the paper
Abstract
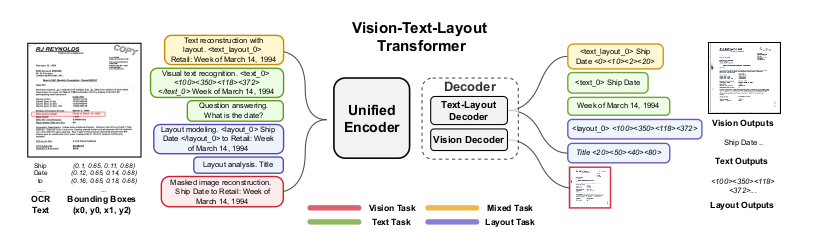
The authors are proposing an architectures:
- Unifies text, image and layout modalities together
- Introducing layout induced architecture
- Homogeneous vocabulary for texts and document layout
- Self-supervised and supervised pretraining
- Unifying multi-domain downstream tasks into a prompt-based sequence generation scheme.
Challenges Tackled
2D Document Layout
For traditional vision-text data, the text modality is usually the high-level description of the corresponding image or task prompt .
When comparing document images with other images used for join embedding models and other classic vision language research, we get to know that in case of document images the text is structurally embedded in the image itself along with other information such as style, figures etc.
For Document AI, the cross modality (text & visual) interactions are much stronger than regular vision language data as the text modality is visually situated in the image at specific layouts.
Unifying Diverse Downstream Tasks
Diverse downstream task as in,
- Document QA
- Layout Detection
- Classification
- Information Extraction
Usually different heads are implemented for these different tasks rendering multiple models based on the task.
In short, these are the 2 challenges:
- How to utilize the strong correlation between image, text and layout modalities and unify them to model the document as a whole?
- How can the model efficiently and effectively learn diverse vision, text, and layout tasks across different domains?
Solution Overview
Classic Encoding Architectures:
- Concatenation of text and visual tokens to a multi-modal transformer
- 2 tower / 3 tower architectures
- Independent encoding for modalities
- Projection heads / fusion networks on top to generate multi-modal representation
- Using joint embedding models (e.g. CLIP) for mapping the modalities
The model architecture consists of the following components:
- A Unified Vision, Text and Layout Encoder (Modal Agnostic Encoder)
- Text-Layout Decoder
- Vision Decoder
Modal Agnostic Encoder
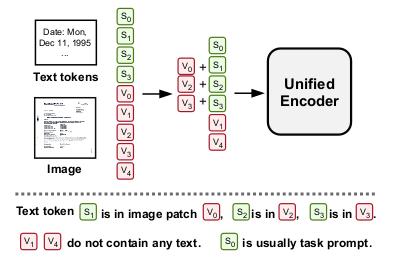
v→ Document Imagesi→ Word Token(x1, y1, x2, y2)i→ LayoutP→ Patch sizePxPxC→ Dimension for the patch size
Each patch is encoded with a D-dim vector, these vectors are then grouped as a sequence of vectors.
Each text tokens are also converted to numerical D-dim embeddings (through vocabulary look-up).
Vision-Text Embeddings
This embedding is a joint representation, its the sum of the text and image patch feature.
si_updated = si + vj
Layout Induced Vision-Text Embeddings
The authors define a layout indicator function for image patch and token embeddings.
- 1 >> if the center of
sifalls within the image patch vj - 0 >> otherwise
si_updated = si + vj | layout indicator == 1 vj_updated = vj | layout indicator == 0
Over here there is no joint embedding for those image patches which have layout indicator as 1. The reason behind this is that the features of these image patches are already integrated with the text embeddings.
These joint representation are then fed to the VTL transformer encoder, this representation greatly enhance the interaction between vision, text and layout in the model input stage.
Discretization Of The Layout Modality
Following the progress achieved in generative object detection, the layout modality is discretized. Continuous coordinates text bbox are converted to layout tokens.
bbox- [x1, y1, x2, y2]- This
bboxis thennormalizedin the rage [0, 1] - The normalized coordinate is then multiplied with the vocabulary size & rounded to the nearest integer.
- normalized
bbox= [0.1, 0.2, 0.5, 0.6] | vocab size = 500 - layout tokens = <50><100><250><300>
Position Bias
Following TILT, 2D text token positions are encoded as 2D relative attention bias (similar to Relative Attention Bias used in T5). Unlike other Document AI transformer models, UDOP doesn’t use 1D position embeddings because:
- Joint Embedding (text + vision)
- 2D Position Bias These 2 incorporate the required information.
Vision-Text-Layout Decoder
There are 2 decoders
- Text-Layout Decoder
- Unidirectional Transformer decoder to generate text & layout tokens
- Follows seq2seq manner
- Vision Decoder
- MAE decoder
- Generating image pixels from test and layout info.
UDOP can generate all vision, text and layout modalities. Both the decoders mentioned above cross-attend to the VTL encoder.
Unified Generative Pre-training
Self Supervised
For the prompt for each of the tasks pls check the paper
Joint Text-Layout Reconstruction (Masked Text-Layout Modeling)
- Masking a percentage of the text token
- Train model to generate tokens and their bbox (layout tokens)
Layout Modeling
- Provide single or group of text tokens along with the document image
- Train the model to generate the positions (layout tokens)
Visual Text Recognition
- Masking ratio ~ 50%
- Identify the text at the given location in the image This objective helps the model to learn the joint vision-text embedding by understanding vision-text correspondence (text present embedded in the image).
Masked Image Reconstruction With Text And Layout
- Reconstruct image with given text & layout
- Add text to the corresponding layout
UDOP implements few modification to the MAE decoding process:
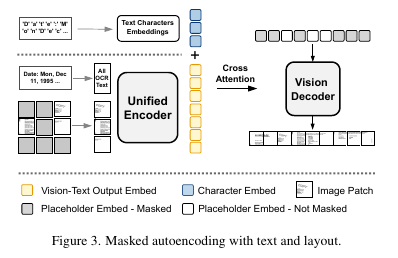
⇒ Cross Attention with Character Embeddings
Vision decoder is modified with a cross attention so that it can attend to both text token encoder feature along with the embeddings of the characters present in the token.
These character embeddings are trainable parameters and not encoded by the encoder.
This cross-attention with characters only adds linear computation complexity but considerably improves the image generation quality.
⇒ Image Decoding
The VTL encoder only outputs the joint vision-text embedding for non masked image patches and these image patches are fused with text tokens. So, these cannot be directly passed to the MAE encoder.
- Vision Decoder takes in seq of trainable placeholder embeddings
- The length & seq order is same as that of the patches of the target image.
- Placeholder classification (2 types of placeholder embeddings)
- To indicate whether the Patch is
masked or not
- To indicate whether the Patch is
Supervised
- Classification
- Prompt : Document Classification on (Dataset Name)
- Layout Analysis
- Prompt : Layout Analysis on (Dataset Name)
- Information Extraction
- Prompt : Information Extraction on (Dataset Name) (Text Query)
- Question Answering
- Prompt : Question Answering on (Dataset Name)
- Document NLI
- Prompt : Document Natural Language Inference on (Dataset Name)
- Target over here is
EntailmentorNot Entailment
Setup Details
UDOP Parameters- 794MUnified Encoder & Text-Layout Decoder- Follows T5-large architectureVision Decoder- Modified MAE DecoderTokenizer- T5 tokenizer and embeddingOptimizer- Adamlr= 5e-5warmup steps- 1000Weight Decay- 1e-2beta1- 0.9 |beta2- 0.98Batch Size- 512Epoch- 1- The pre-trained model is fine-tuned on each of the evaluation dataset
⇒ Curriculum Learning
For the tasks which UDOP attends to the document image resolution matters a lot. The authors use large resolution (1024). For low resolution the document text is unidentifiable for both detection and generation.
For larger resolutions (1024), (1024 / 16)^2 = 4096 image patch seq. This will slow down the training compared to low resolutions (224). Therefore, the authors use curriculum learning to scale the resolutions from 224 to 1024 ( 224 → 512 → 1024 ).
Performance Overview
Noting the visualization tasks mentioned in the paper:
- Masked Image Reconstruction
- Document Generation & Editing
- Layout Customization
For the all the ablations check the paper
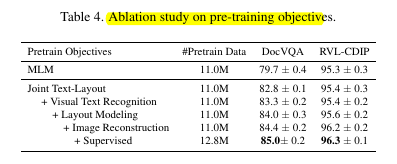
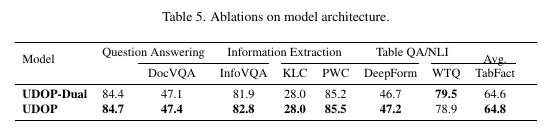
⇒ Ablation on Model Architecture
UDOP-dual - The authors separate the Unified Encoder into text encoder (text and layout) and a vision encoder. The study shows that having one unified encoder is better than having separate encoders for most of the cases (there are exceptions)
⇒ Ablation on Vision Modality
Vision modality is more prominent for visually rich tasks. As shown below, the vision modality helps more for InfoVQA when compared to DocVQA.
